When Point Metrics Mislead
Structure-Aware Evaluation Reveals Conditional Ranking Shifts in Time Series Anomaly Detection
Abstract
Time series anomaly detection is commonly reported with point-wise metrics such as AUC-ROC, while many benchmark anomalies are sustained temporal segments. This project evaluates when point-level and segment-aware metrics induce different pairwise model rankings, and provides a lightweight reproducibility artifact for validating the reported ranking-shift observations.
Key Findings
| Finding | Summary |
|---|---|
| Ranking flips | Pairwise orderings differ between AUC-ROC and Aff-F1 in 14/60 deep-model comparisons and 44/126 comparisons when classical baselines are included. |
| Benchmark structure | Under the processed labels used in this artifact, four industrial benchmarks contain no short anomaly segments. |
| SAEScore usage | SAEScore is reported as a composite summary to expose reporting regimes, not as a universal replacement for constituent metrics. |
| TSB-AD-M audit scale | The TSB-AD-M replication audit covers 25 models, 180 multivariate series, and 4,498 recomputed model-series rows. |
Figures
Figure 1. Anomaly-duration taxonomy
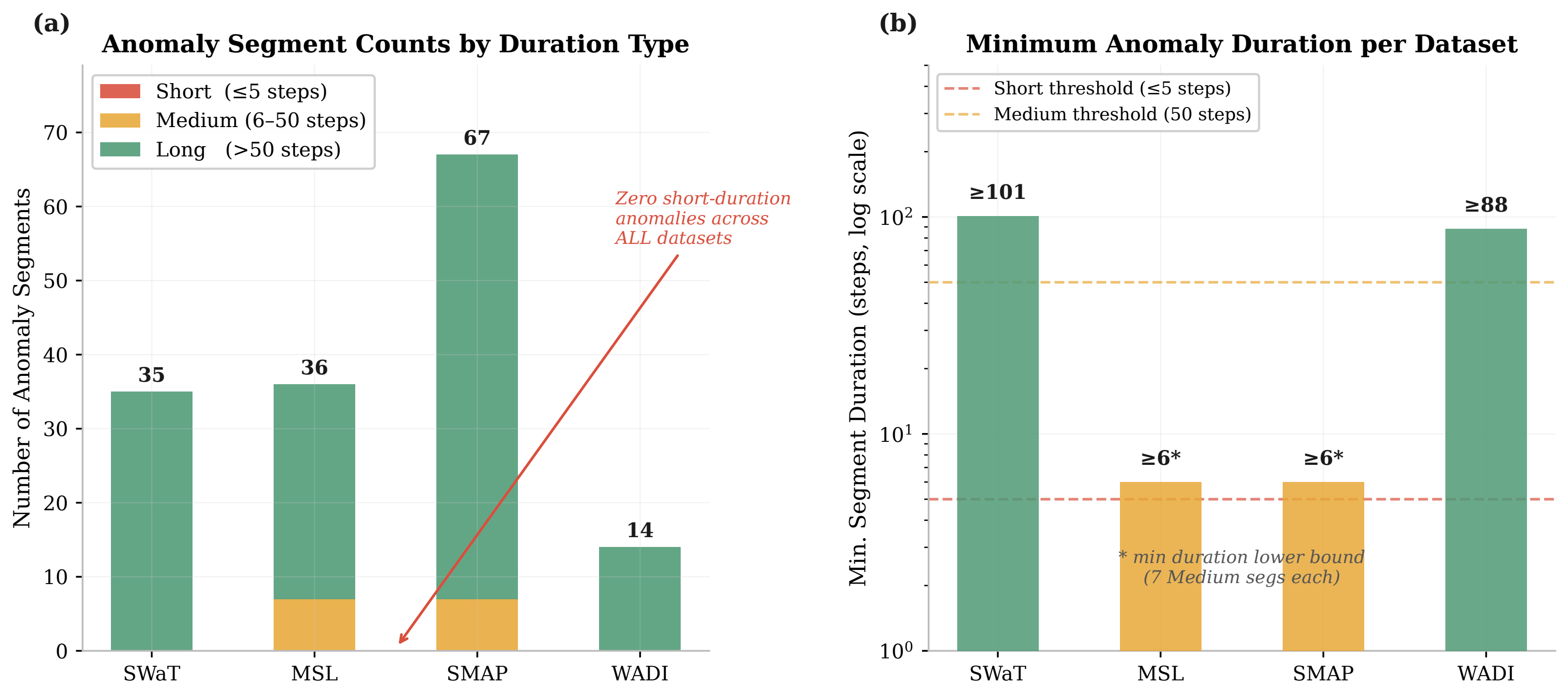
Paper Figure 1 shows duration-stratified anomaly taxonomy across SWaT, MSL, SMAP, and WADI, computed using the processed label definitions retained in this artifact.
Open vector PDFFigure 4. AUC-ROC versus Aff-F1
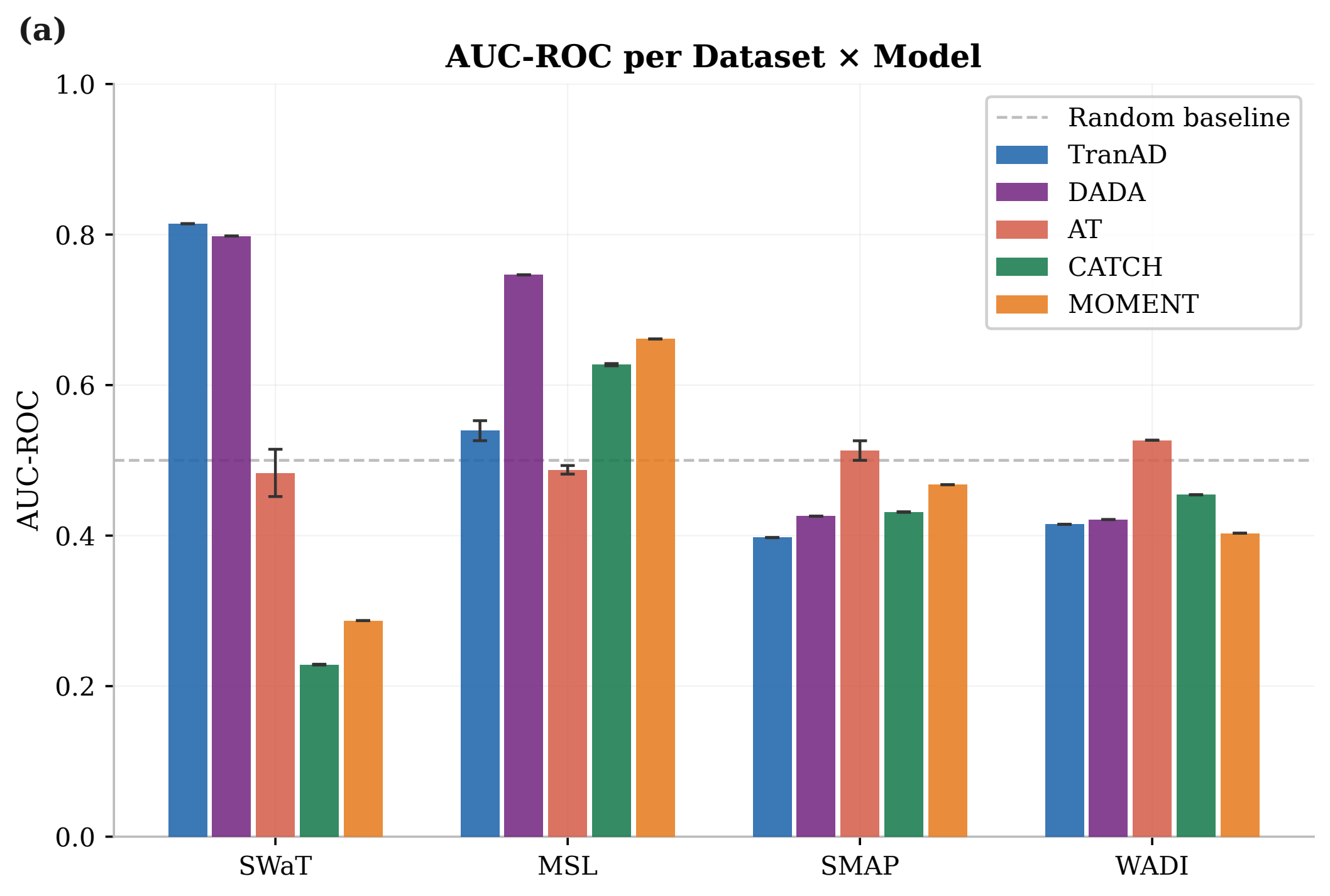
Paper Figure 4 compares AUC-ROC and Aff-F1, highlighting pairwise ranking discrepancies between point-level reporting and segment-aware evaluation across benchmark configurations.
Open vector PDFFigure 5. TSB-AD-M replication audit
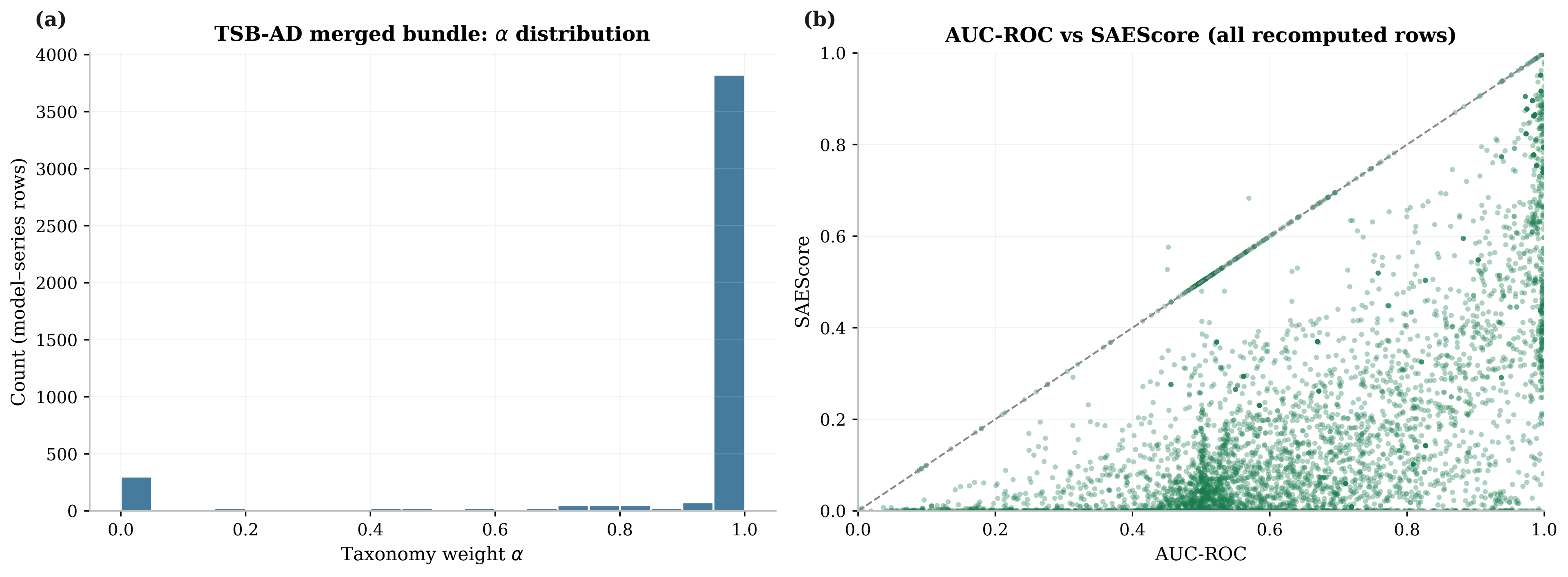
Paper Figure 5 presents the TSB-AD-M replication audit, showing taxonomy-weight distributions and the AUC-ROC versus SAEScore relationship across recomputed model-series rows.
Open vector PDFFigure 13. Bootstrap rank comparison
Paper Figure 13 reports bootstrap-based rank comparisons between AUC-ROC and SAEScore, estimated under repeated resampling to characterize ranking uncertainty and stability.
Open vector PDFReproducibility Artifact
- Derived summaries required to reproduce the reported evaluation tables and checks.
- Validation scripts for rank-flip counting, alpha-stratified analysis, and bootstrap comparison.
- Lightweight tests for consistency checks on retained artifact outputs.
- No raw access-controlled datasets are redistributed; users must obtain upstream datasets independently.
python scripts/validate_tab_rfr_counts.py python scripts/compute_tsbad_alpha_stratified_rfr.py python scripts/compute_rfr_bootstrap_ci.py --n-boot 100
Citation
@misc{ko2026pointmetricsmislead,
title={When Point Metrics Mislead: Structure-Aware Evaluation Reveals Conditional Ranking Shifts in Time Series Anomaly Detection},
author={Ko, Youngmin},
year={2026},
note={arXiv preprint, arXiv ID coming soon}
}